So you know what fuzzing is, and maybe you've tried it yourself. (If you don't, read my previous post and get caught up.) If you're lucky, you even have a crash or two. The obvious next step is to find out why your file crashed your target application*. During the fuzzing process, you probably used a tool such as zzuf or peach to mutate a certain amount of a file. (These tools work by taking your original file, changing a few bytes here and there, and generating a new file that contains those differences.) Depending on how you use them, these tools can make anywhere from a few dozen to several thousands of changes to your file. The question then becomes, "Which of these changes caused the crash?" Answering that question is the first step in a process known as reverse engineering.
The process of finding out which changes actually matter is usually time-consuming and frustrating. The idea is that you take your mutated file and slowly un-mutate it until you find out which part crashed your target. The opposite method can also be applied, where you take your original file and slowly apply the same mutations that exist in your crash file until you find the differences that matter. The name I like to give to those certain changes that cause the crash are the magic bytes.
Finding the magic byte is tricky and it takes forever. Ain't nobody got time fo dat! Programmers are lazy and impatient. I wanted a tool where I could just feed in the file I started with and the file that causes crashes, and it would do all the work for me and make a handy list of the magic bytes. Unfortunately, I couldn't seem to find any such tool. After a few minutes of digging about on the googlez, I decided to make one myself. I needed to come up with an algorithm, then, that would find the magic byte in the least amount of time possible.
Let's look at this problem graphically. I'm not really a visual person, but I've found that it's easier to explain things with pictures. Here's a beauty I came up with in mspaint:
"It's a box", you say. Your shape recognition skills are off the charts, you're ready to move on to 1st grade. Here we go.
Let's imagine that this box represents your mutated file. Somewhere in this file is a magical byte that will lead to happiness and never-ending rainbows. I'm going to represent that byte with a dot.
So let's say that there are 100 differences between your original file and your mutated file. You don't know where that dot is. How do you find it?
The Obvious Way:
Programmers are lazy. If you want the answer but you don't want to actually have to think, you could just make 100 files that contain one difference each and test all of them until something crashes. This method is really slow, but it does work most of the time (stay tuned for the part where I talk about why it doesn't always work). The thing is, you don't want to have to test 100 individual files. Lucky for us, it's easy to double the efficiency!
The Obvious Way 2.0:The Obvious Way:
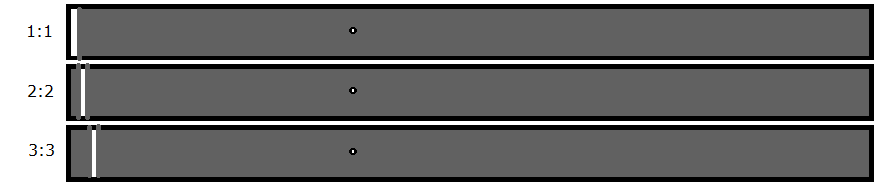 |
| The white parts are diffs that got kept, the grey parts are diffs that didn't get written. The resulting file only crashes if the dot is in the white zone. |
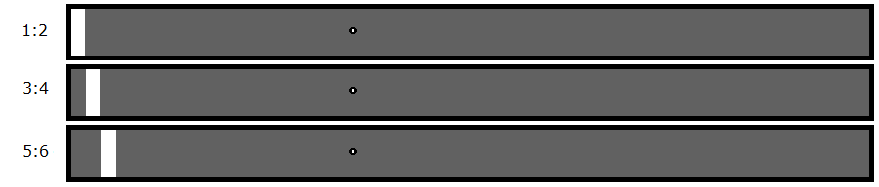
So now we only have to load a maximum of 52 files. The first 50 would narrow down the diffs to the last two, then you'd test each of those two individually. That's way more efficient than The Obvious Solution 1.0, right? But hang on, if keeping more bytes per file gives you more efficiency, then the best way would be to keep all the bytes? Most of the bytes? As I'm sure you've figured out by now, the smarter way to do it would be to cut the box in half.
The Smart Way:

Bam, now we've got a crash within the first two tests and you already know that half of the differences don't matter. The best thing to do at this point is to repeat The Smart Way using your new file that only contains 50 differences as the mutated file. It's going to look something like this:
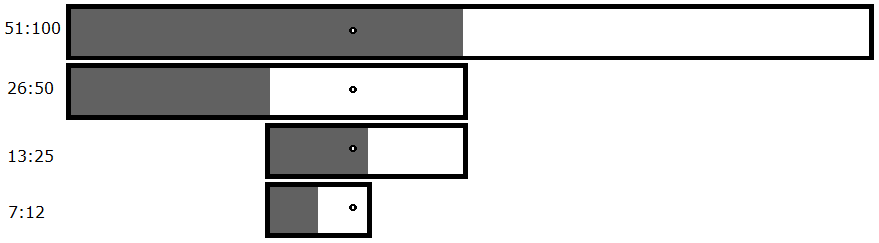
Programmers call this type of structure a binary tree. There are two possible outcomes for each test:
The Problem:
Put simply, how do you know that only one changed byte is required to cause the crash? The crash could very easily be caused by multiple bytes working together.
- All of the magic bytes were in the range you tested, and the file crashed
- None of the magic bytes were in the range you tested, and the file did not crash
The Problem:
Put simply, how do you know that only one changed byte is required to cause the crash? The crash could very easily be caused by multiple bytes working together.
 |
| In this scenario, neither file would crash. This is because in order for this crash to happen, both bytes must be present--that is, both dots must be in the white zone. |
A binary search fails in this case; we need a new solution that works for two-byte scenarios. When you start looking for magic bytes, you have no indication of how many there are going to be. This means that you have to have one solution that's optimal for both one and two byte scenarios. You can't use a classic binary tree anymore because they're dependent on the fact that if something's not in one half, it's going to be in the other half. You don't know that anymore; there are actually three possible outcomes now:
The Smart Way 2.0:
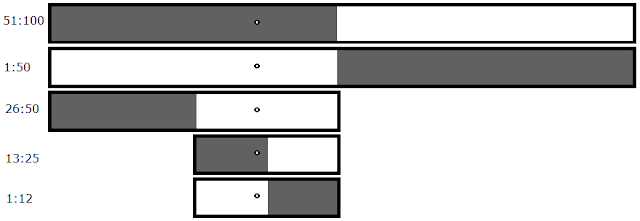
For one magic byte, the new maximum number of files you have to test is 14. The minimum number of files you'd have to test is 7 (that's if it crashes every time). (Mathematically, that's a maximum of 2(log2n), a minimum of log2n, and an average of 1.5(log2n).) This is because you now have to test both halves; you can't narrow anything down until you actually find a crash. In the event that neither file crashes, you know you're dealing with a bug that requires a minimum of two magic bytes.
If the two magic bytes are near each other in the file, you may be able to eliminate a large portion of the useless changes in the fastest possible way before you realize that there are two bytes. Eventually, though, you're going to get to a point where neither file crashes. What do you do at this point? You'll need a new algorithm.
The Smart Way 3.0:
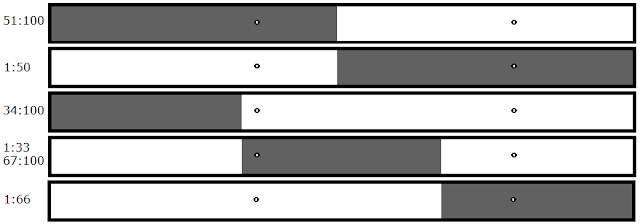 As I previously mentioned, the first two files wouldn't crash. After you've exhausted the most optimal way of eliminating diffs that don't matter (keeping 1/2 of the diffs), you move on to the next most optimal way, which is to keep 2/3 of the file. Doing this creates the third file, which eliminates the maximum amount of useless diffs while still crashing.
As I previously mentioned, the first two files wouldn't crash. After you've exhausted the most optimal way of eliminating diffs that don't matter (keeping 1/2 of the diffs), you move on to the next most optimal way, which is to keep 2/3 of the file. Doing this creates the third file, which eliminates the maximum amount of useless diffs while still crashing.
If there is one magic byte, you'll only ever need to break the file in two pieces. If there are two magic bytes, you'll need to break the file into three pieces to find those two magic bytes. If you're keeping 2/3 of the file and none of the three files crash, you have at least three bytes that are required to cause your crash. The number of pieces you need to break the file into is always one more than the number of magic bytes there are. Therefore, once you break the file into three pieces, you don't go back to breaking it into two pieces again.
Another Outcome?
Although the third file crashes in the example above, what happens if you still test files four and five? If you eliminate the first third as unimportant as in the example above, then when testing the remaining two files you're actually testing the file in halves. Because you know you have a minimum of two bytes at this point (the only reason you'd move from halves to thirds is if you have at least two bytes), and because the number of pieces you need to break the file into is always one more than the number of magic bytes there are, files four and five will never crash. This means that if files four or five do crash, you have multiple bugs in your crash file.
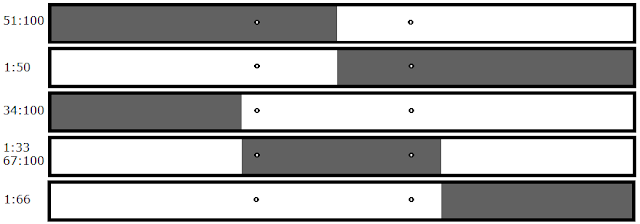
This can most easily be seen looking at a simpler scenario, so let's move back to testing halves. There are actually four outcomes, not three:
 As you can see, files one and three both crash which would normally indicate that there were two bugs. This is a simple example of a false positive. This situation would never occur if you start with halves instead of thirds.
As you can see, files one and three both crash which would normally indicate that there were two bugs. This is a simple example of a false positive. This situation would never occur if you start with halves instead of thirds.
The Problem:
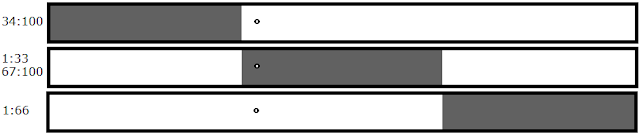
As those of you who aren't lost yet may have noticed, there is actually one situation in which you can still have a false positive when testing for multi-bug scenarios. This occurs only if there are two magic bytes in the middle third of the list of diffs, but on opposite halves of the file. (This false positive does not occur when moving to fourths or fifths, only thirds.) It looks like this:
- All of the magic bytes were in the range you tested, and the file crashed
- None of the magic bytes were in the range you tested, and the file did not crash
- Some of the magic bytes are in the range you tested and some are not, so the file did not crash
It's the addition of this third possibility that breaks binary searching. You can, however, modify the classic binary search slightly in order to account for this.
The Smart Way 2.0:
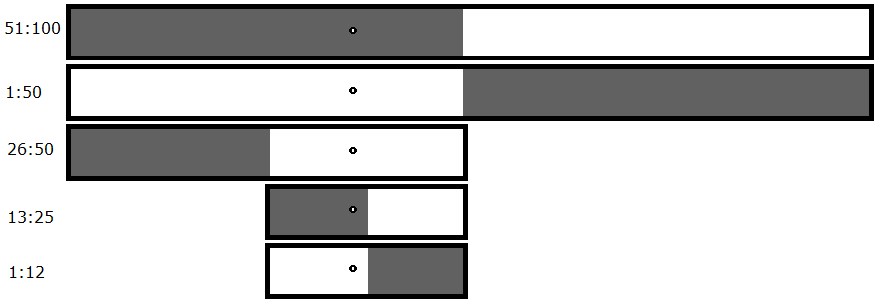
For one magic byte, the new maximum number of files you have to test is 14. The minimum number of files you'd have to test is 7 (that's if it crashes every time). (Mathematically, that's a maximum of 2(log2n), a minimum of log2n, and an average of 1.5(log2n).) This is because you now have to test both halves; you can't narrow anything down until you actually find a crash. In the event that neither file crashes, you know you're dealing with a bug that requires a minimum of two magic bytes.
If the two magic bytes are near each other in the file, you may be able to eliminate a large portion of the useless changes in the fastest possible way before you realize that there are two bytes. Eventually, though, you're going to get to a point where neither file crashes. What do you do at this point? You'll need a new algorithm.
The Smart Way 3.0:
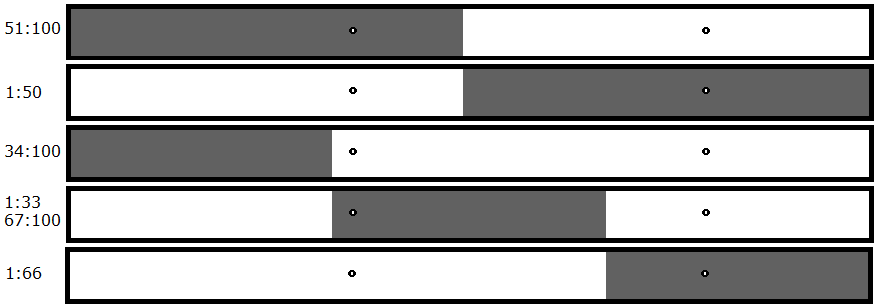
If there is one magic byte, you'll only ever need to break the file in two pieces. If there are two magic bytes, you'll need to break the file into three pieces to find those two magic bytes. If you're keeping 2/3 of the file and none of the three files crash, you have at least three bytes that are required to cause your crash. The number of pieces you need to break the file into is always one more than the number of magic bytes there are. Therefore, once you break the file into three pieces, you don't go back to breaking it into two pieces again.
Another Outcome?
Although the third file crashes in the example above, what happens if you still test files four and five? If you eliminate the first third as unimportant as in the example above, then when testing the remaining two files you're actually testing the file in halves. Because you know you have a minimum of two bytes at this point (the only reason you'd move from halves to thirds is if you have at least two bytes), and because the number of pieces you need to break the file into is always one more than the number of magic bytes there are, files four and five will never crash. This means that if files four or five do crash, you have multiple bugs in your crash file.
This can most easily be seen looking at a simpler scenario, so let's move back to testing halves. There are actually four outcomes, not three:
- The first half contains all the magic bytes (resulting in a crash)
- The second half contains all the magic bytes (resulting in a crash)
- Some of the magic bytes are in the first half, some are in the second half (neither half crashes)
- Both halves of the file contain a complete set of magic bytes (both halves crash, two bugs are present)
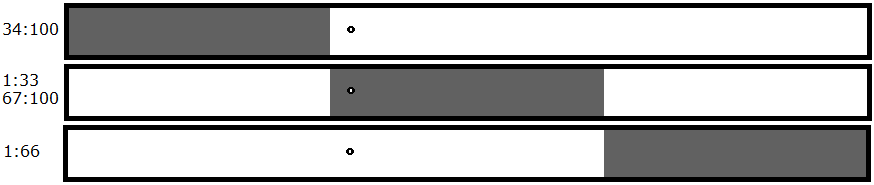
The Problem:
As those of you who aren't lost yet may have noticed, there is actually one situation in which you can still have a false positive when testing for multi-bug scenarios. This occurs only if there are two magic bytes in the middle third of the list of diffs, but on opposite halves of the file. (This false positive does not occur when moving to fourths or fifths, only thirds.) It looks like this:
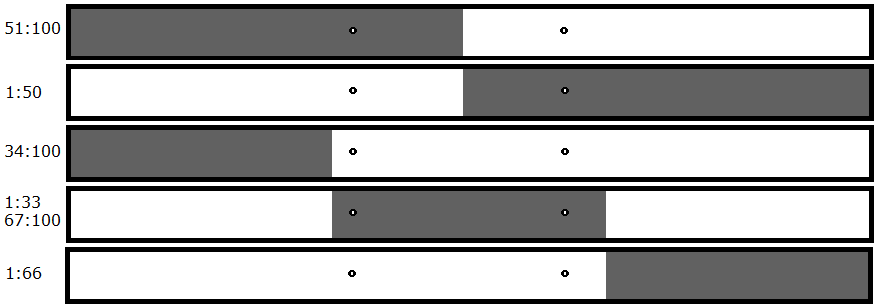
Multiple files crash in the same testing stage (thirds), but there's clearly only one bug present. Luckily, this is the only false positive present when looking for multiple bugs, and it's easily tested for.
The Solution:

If the algorithm detects two bugs in the thirds stage of testing, all you have to do is test to see if this is the result of files one and three (in this case 34:100 and 1:66), and if so, test just the middle third. If the middle third does not crash then you do in fact have two bugs, but if the middle third does crash then you've successfully detected the false positive. In that case, you can continue testing using just the middle third.
What's Left?
Tired yet? We're pretty much done. The only thing left to do is write the code, which I've mostly done for you. You can get the current version of bytefinder on my GitHub. It includes two modes, which correspond to the two best solutions above.
The first mode is normal mode, in which you give it a file and a mutated version of that file which causes a crash. The program then looks for magicbytes while taking into account that there could be multiple bugs. It will find the bug that requires the fewest amount of magic bytes for you, and list what they are. (Currently, it does not find all the magic bytes for the second bug. This is on my list of things to do.)
The second mode, quick mode, is used by passing
So what does it look like?
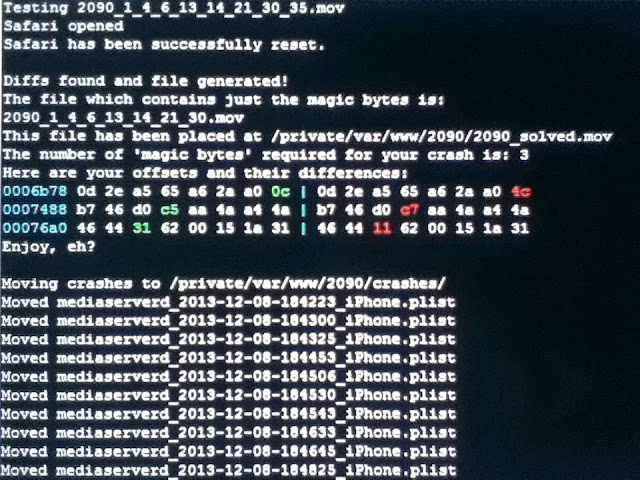
Your magic bytes are listed for you and a file that only contains those differences is generated. =) If you'd like to learn more about what to do next or reverse engineering in general, I recommend checking out this post by dirkg.
I'm sure you have questions about this post. Feel free to comment below, or contact me on twitter @compiledEntropy. I'll be happy to answer whatever questions you have. If you think of ways to improve my methods or find faults with them, I'm open to criticism as well. That's all for now! Enjoy, eh?
Important note:
bytefinder is not built to handle kernel panics. It will eventually be upgraded to handle them, I'm working on this now, but the optimization is going to be completely different. If you're a math wizard and you want to help, contact me on twitter to discuss specifics.
The Solution:

If the algorithm detects two bugs in the thirds stage of testing, all you have to do is test to see if this is the result of files one and three (in this case 34:100 and 1:66), and if so, test just the middle third. If the middle third does not crash then you do in fact have two bugs, but if the middle third does crash then you've successfully detected the false positive. In that case, you can continue testing using just the middle third.
What's Left?
Tired yet? We're pretty much done. The only thing left to do is write the code, which I've mostly done for you. You can get the current version of bytefinder on my GitHub. It includes two modes, which correspond to the two best solutions above.
The first mode is normal mode, in which you give it a file and a mutated version of that file which causes a crash. The program then looks for magicbytes while taking into account that there could be multiple bugs. It will find the bug that requires the fewest amount of magic bytes for you, and list what they are. (Currently, it does not find all the magic bytes for the second bug. This is on my list of things to do.)
The second mode, quick mode, is used by passing
-q as a parameter. This mode is slightly faster, but it doesn't detect whether there could be multiple bugs present. It will always find the bug that requires the fewest amount of magic bytes.So what does it look like?
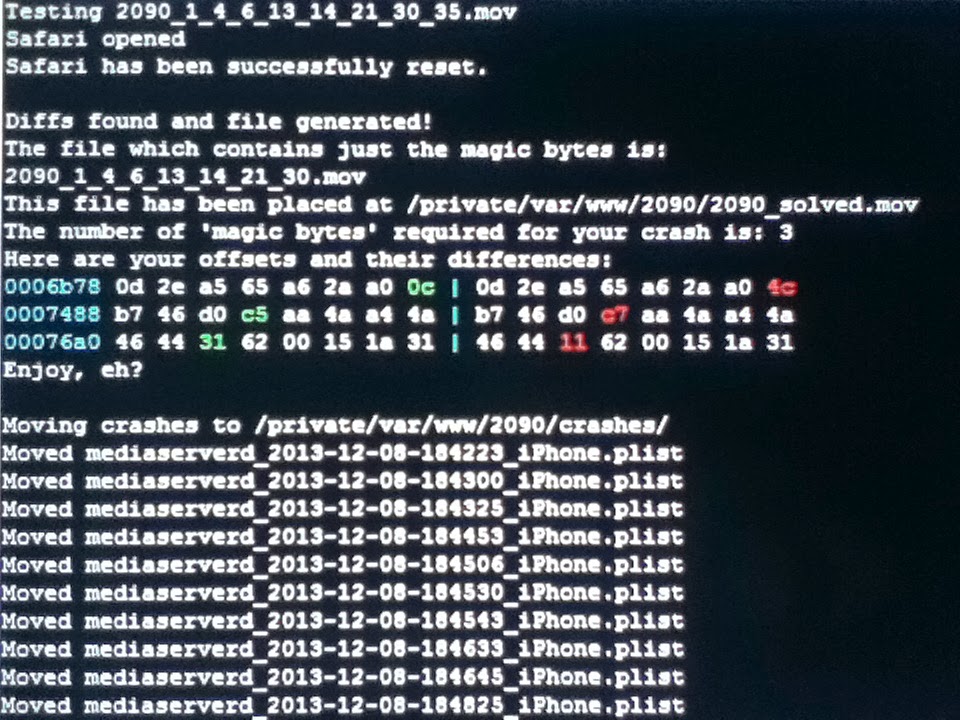
Your magic bytes are listed for you and a file that only contains those differences is generated. =) If you'd like to learn more about what to do next or reverse engineering in general, I recommend checking out this post by dirkg.
I'm sure you have questions about this post. Feel free to comment below, or contact me on twitter @compiledEntropy. I'll be happy to answer whatever questions you have. If you think of ways to improve my methods or find faults with them, I'm open to criticism as well. That's all for now! Enjoy, eh?
Important note:
bytefinder is not built to handle kernel panics. It will eventually be upgraded to handle them, I'm working on this now, but the optimization is going to be completely different. If you're a math wizard and you want to help, contact me on twitter to discuss specifics.
*The tool I wrote is built to automate this process for MobileSafari on iOS because that's my target. The methods discussed for fuzzing applications and reverse engineering crashes are valid for pretty much any target, however.
Acknowledgements:
Huge, massive props to uroboro for implementing my crazy feature requests into hexdiff, which my tool is completely dependent on. Without it, it would be extremely difficult to interact with differences between files in a way that allows for such fine-grained control.
Acknowledgements:
Huge, massive props to uroboro for implementing my crazy feature requests into hexdiff, which my tool is completely dependent on. Without it, it would be extremely difficult to interact with differences between files in a way that allows for such fine-grained control.
No comments:
Post a Comment